Vector
1.介绍
Vector 是一款日志采集器,通常用作 logstash 的替代品,logstash 属于 ELK 生态,使用广泛,但是性能不太好。Vector 使用 Rust 编写,声称比同类方案快 10 倍。
Vector 不止是收集、路由日志数据,也可以路由指标数据,甚至可以从日志中提取指标,功能强大。下面是 Vector 的架构图:
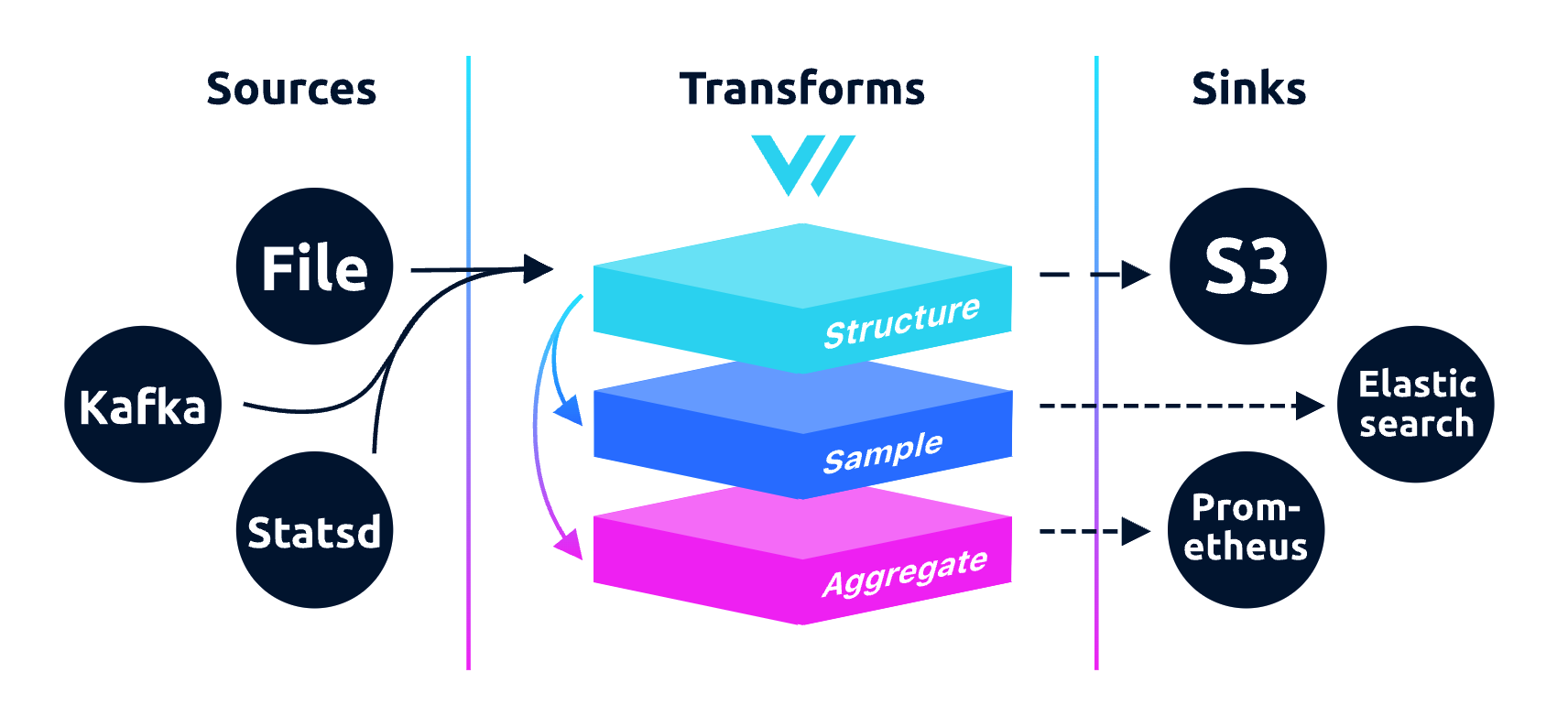
sources:- 负责从不同的数据源采集日志或指标数据
- 可以是文件、网络、消息队列等,Sources 是 Vector 数据流的起点,支持多种输入来源(如 Kafka、文件系统、HTTP 请求等)
transforms:- 转换,负责处理或转化数据流。
- 如过滤、重命名字段、增加新的字段、解析日志格式等,是修改数据,使其更符合目标的需求
sinks:- 汇聚,负责将处理后的数据发送到指定的目标位置(如 Elasticsearch、Prometheus、文件系统等)。
- Sinks 是 Vector 数据流的终点,用于输出或存储最终的日志数据。
2.大规模数据处理
生产级别大规模的数据处理流:
- file --> vector --> kafka --> Java项目 --> es
以我司的流程为例:
2.1.日志
日志文件落盘格式名为 car.log,日志的格式为:
json
{
"log_info": "datapk output array is 0. - Queue.cpp:318",
"appid": "252822e2",
"service": {
"type": "dfir"
},
"log_time": "2024-07-26T15:53:55.696Z",
"@timestamp": "2024-07-26T07:53:57.555Z",
"host": {
"name": "fecab7864d98",
"ip": "10.XXX.XXX.22"
},
"component_name": "ds",
"sid": "wgw000cb9be@dx190ee0836bba14e532",
"component_type": "dFirServer",
"uid": "db1dcb8d8e8dcb532d4172fdf6971b_1",
"log_level": "ERROR",
"pid": "255",
"@version": "1",
"applicationCode": "car_dfir",
"sopLogType": "car_dfir_log"
}2.2.vector配置
vector 需要配置 sources、transforms、sinks,分别介绍作用:
2.2.1.sources
关于 sources 的配置:
提示:
在 Vector 中,sources 是数据流的起点,负责从不同的来源采集日志或指标数据。根据需要,sources 可以从多种数据源收集数据,以下是一些常见的 sources 类型:
File Source:从文件系统中读取日志文件Syslog Source:从 Syslog 服务器或本地 Syslog 服务接收日志Kafka Source:从 Kafka 消息队列中消费消息HTTP Source:通过 HTTP 接口接收日志数据TCP/UDP Source:通过 TCP 或 UDP 协议接收数据
toml
# 读取日志文件
[sources.my_source_id]
type = "file"
include = [ "/var/log/**/*.log" ] #日志文件路径,可以配多个,也可以使用通配符2.2.2.transforms
关于 transforms 的配置:
提示:
如果原始数据足够完美无需任何处理,那么这一块可以忽略,但是实际上大部分情况下还是需要这一步的,这里介绍最常用的“变换”,详细请看:transforms
remap- 在 vector 中使用 VRL(Vector Remap Language,一种面向表达式的语言),旨在以安全和高性能的方式处理可观察性数据
filter- 用于根据特定条件筛选数据,决定哪些数据应该继续流向后续的处理环节,哪些数据应该被丢弃
transforms 可以在配置中同时使用 remap 和 filter,并且 transforms 的 inputs 可以是 sources,也可以是其他的 transforms:
toml
# 日志内容处理
[transforms.my_transform_id]
type = "remap" # 指定了transform的类型为 "remap",用于在Vector中修改数据的字段
inputs = ["my_source_id"] # 指定此transform的输入源为名为 "my_source_id" 的源(source)
# 将 message 字段的内容转换成字符串,将字符串内容解析为 JSON 格式
# 在解析后的 message JSON 对象中添加一个名为 applicationCode 的新字段,并将其值设置为 "1234"
# 添加一个名为 sopLogType 的新字段,并将其值设置为 "type001"
source = '''
.message = parse_json!(string!(.message))
.message.applicationCode = "1234"
.sopLogType = "type001"
'''
[transforms.filter_logs]
type = "filter"
inputs = ["my_transform_id"]
condition = '.message.level == "error"' # 只保留 level 为 "error" 的日志2.2.3.sinks
关于 sinks 的配置:
toml
# 日志输出,将日志内容输出到kafka集群
[sinks.kafka_cluster]
type = "kafka" #日志会发送到 Kafka 消息队列
inputs = ["filter_logs"] #输入源是 filter_logs,即先前在 transforms 中定义的、已经经过处理的日志数据
bootstrap_servers = "172.xx.xx.xxx:9092,172.xx.xx.xxx:9092,172.xx.xx.xxx:9092" #Kafka 集群地址,指定了三个 Kafka 节点地址,提高集群的容错性,防止某个节点宕机时无法连接到 Kafka
topic = "test_topic" #将日志发送到 Kafka 集群中的哪个 topic
encoding.codec = "text" #日志数据的编码格式,输出的日志将作为纯文本格式发送到 Kafka
batch.max_bytes = 10485760 #批量发送的最大字节数
batch.max_events = 10000 #每个批次最多可以包含的日志事件数量
# 如果在这 1 秒内,当前的批次还没有达到事件数量或字节数的限制,Vector 会强制发送当前批次中的日志事件
batch.timeout_secs = 1 #新事件加入批次的最大时间3.小规模数据处理
小规模的数据采集,也可以不用kafka:
- json文件 --> vector --> es/http
其实前面的 sources 和 transforms 配置都一样,只需要将 sinks 改为 es/http 即可:
toml
# es
[sinks.elasticsearch]
type = "elasticsearch"
inputs = ["my_transform"]
endpoint = "http://localhost:9200"
index = "logs-%Y-%m-%d"
auth.user = "elastic"
auth.password = "password"
# http
[sinks.http]
type = "http"
inputs = ["my_transform"]
uri = "http://example.com/api/logs"
method = "POST"
encoding.codec = "json"