JavaSE
学习参考资料:
6.1.集合类
集合类是Java中非常重要的存在,使用频率极高。
集合类其实就是为了更好地组织、管理和操作数据而存在的,包括列表、集合、队列、映射等数据结构。
集合跟数组一样,可以表示同样的一组元素,但是他们的相同和不同之处在于:
- 它们都是容器,都能够容纳一组元素。
不同之处:
- 数组的大小是固定的,集合的大小是可变的。
- 数组可以存放基本数据类型,但集合只能存放对象。
- 数组存放的类型只能是一种,但集合可以有不同种类的元素。
6.1.1.集合根接口
所有的集合类最终都是实现自集合根接口的Collection接口:
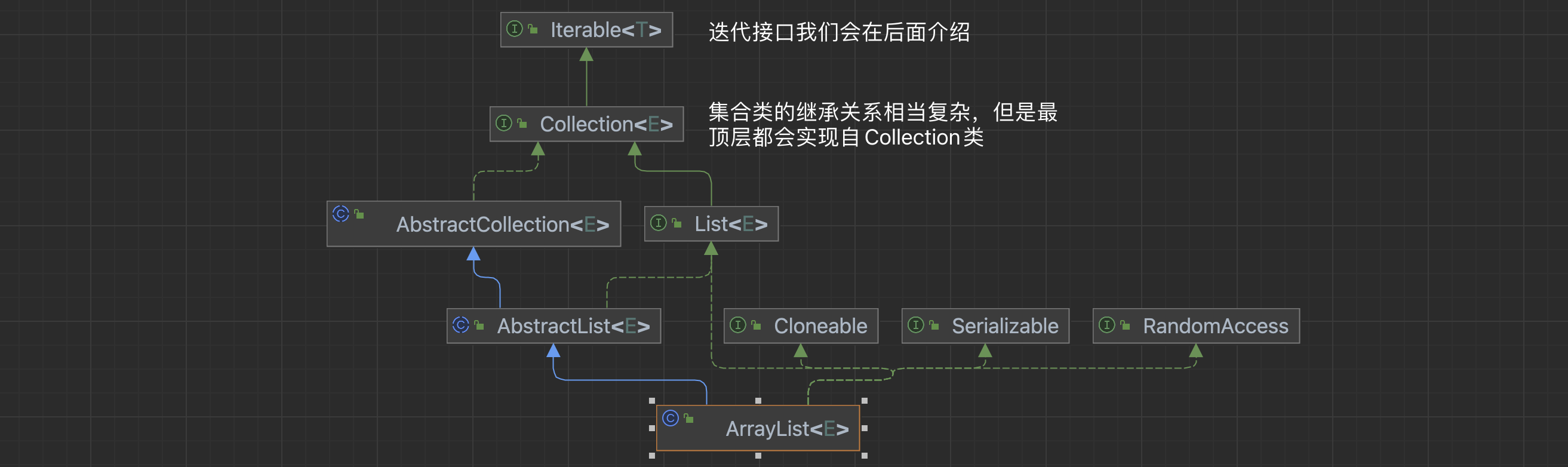
这个接口定义了集合类的一些基本操作:
public interface Collection<E> extends Iterable<E> {
//-------这些是查询相关的操作----------
//获取当前集合中的元素数量
int size();
//查看当前集合是否为空
boolean isEmpty();
//查询当前集合中是否包含某个元素
boolean contains(Object o);
//返回当前集合的迭代器,我们会在后面介绍
Iterator<E> iterator();
//将集合转换为数组的形式
Object[] toArray();
//支持泛型的数组转换,同上
<T> T[] toArray(T[] a);
//-------这些是修改相关的操作----------
//向集合中添加元素,不同的集合类具体实现可能会对插入的元素有要求,
//这个操作并不是一定会添加成功,所以添加成功返回true,否则返回false
boolean add(E e);
//从集合中移除某个元素,同样的,移除成功返回true,否则false
boolean remove(Object o);
//-------这些是批量执行的操作----------
//查询当前集合是否包含给定集合中所有的元素
//从数学角度来说,就是看给定集合是不是当前集合的子集
boolean containsAll(Collection<?> c);
//添加给定集合中所有的元素
//从数学角度来说,就是将当前集合变成当前集合与给定集合的并集
//添加成功返回true,否则返回false
boolean addAll(Collection<? extends E> c);
//移除给定集合中出现的所有元素,如果某个元素在当前集合中不存在,那么忽略这个元素
//从数学角度来说,就是求当前集合与给定集合的差集
//移除成功返回true,否则false
boolean removeAll(Collection<?> c);
//Java8新增方法,根据给定的Predicate条件进行元素移除操作
default boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
boolean removed = false;
final Iterator<E> each = iterator(); //这里用到了迭代器,我们会在后面进行介绍
while (each.hasNext()) {
if (filter.test(each.next())) {
each.remove();
removed = true;
}
}
return removed;
}
//只保留当前集合中在给定集合中出现的元素,其他元素一律移除
//从数学角度来说,就是求当前集合与给定集合的交集
//移除成功返回true,否则false
boolean retainAll(Collection<?> c);
//清空整个集合,删除所有元素
void clear();
//-------这些是比较以及哈希计算相关的操作----------
//判断两个集合是否相等
boolean equals(Object o);
//计算当前整个集合对象的哈希值
int hashCode();
//与迭代器作用相同,但是是并行执行的,我们会在下一章多线程部分中进行介绍
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
//生成当前集合的流,我们会在后面进行讲解
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
//生成当前集合的并行流,我们会在下一章多线程部分中进行介绍
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
}6.1.2.List列表
List是集合类型的一个分支,它的主要特性有:
- 是一个有序的集合,插入元素默认是插入到尾部,按顺序从前往后存放,每个元素都有一个自己的下标位置
- 列表中允许存在重复元素
在List接口中,定义了列表类型需要支持的全部操作,List直接继承自前面介绍的Collection接口,其中很多地方重新定义了一次Collection接口中定义的方法,这样做是为了更加明确方法的具体功能:
//List是一个有序的集合类,每个元素都有一个自己的下标位置
//List中可插入重复元素
//针对于这些特性,扩展了Collection接口中一些额外的操作
public interface List<E> extends Collection<E> {
...
//将给定集合中所有元素插入到当前结合的给定位置上(后面的元素就被挤到后面去了,跟我们之前顺序表的插入是一样的)
boolean addAll(int index, Collection<? extends E> c);
...
//Java 8新增方法,可以对列表中每个元素都进行处理,并将元素替换为处理之后的结果
default void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final ListIterator<E> li = this.listIterator(); //这里同样用到了迭代器
while (li.hasNext()) {
li.set(operator.apply(li.next()));
}
}
//对当前集合按照给定的规则进行排序操作,这里同样只需要一个Comparator就行了
@SuppressWarnings({"unchecked", "rawtypes"})
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
...
//-------- 这些是List中独特的位置直接访问操作 --------
//获取对应下标位置上的元素
E get(int index);
//直接将对应位置上的元素替换为给定元素
E set(int index, E element);
//在指定位置上插入元素,就跟我们之前的顺序表插入是一样的
void add(int index, E element);
//移除指定位置上的元素
E remove(int index);
//------- 这些是List中独特的搜索操作 -------
//查询某个元素在当前列表中的第一次出现的下标位置
int indexOf(Object o);
//查询某个元素在当前列表中的最后一次出现的下标位置
int lastIndexOf(Object o);
//------- 这些是List的专用迭代器 -------
//迭代器我们会在下一个部分讲解
ListIterator<E> listIterator();
//迭代器我们会在下一个部分讲解
ListIterator<E> listIterator(int index);
//------- 这些是List的特殊转换 -------
//返回当前集合在指定范围内的子集
List<E> subList(int fromIndex, int toIndex);
...
}列表中允许存在相同元素,可以添加两个一模一样的。
那如果删除对象呢,是一起删除还是只删除一个呢❓
- 只会删除排在前面的第一个元素。
6.1.3.迭代器
集合类都是支持使用 foreach 语法的:
public static void main(String[] args) {
List<String> list = Arrays.asList("A", "B", "C");
for (String s : list) { //集合类同样支持这种语法
System.out.println(s);
}
}但是由于仅仅是语法糖,实际上编译之后:
public static void main(String[] args) {
List<String> list = Arrays.asList("A", "B", "C");
Iterator var2 = list.iterator(); //这里使用的是List的迭代器在进行遍历操作
while(var2.hasNext()) {
String s = (String)var2.next();
System.out.println(s);
}
}使用迭代器,可以实现对集合中的元素的进行遍历。一个迭代器,默认有一个指向集合中第一个元素的指针:

每一次 next 操作,都会将指针后移一位,直到完成每一个元素的遍历,此时再调用 next 将不能再得到下一个元素。
public interface Iterator<E> {
//看看是否还有下一个元素
boolean hasNext();
//遍历当前元素,并将下一个元素作为待遍历元素
E next();
//移除上一个被遍历的元素(某些集合不支持这种操作)
default void remove() {
throw new UnsupportedOperationException("remove");
}
//对剩下的元素进行自定义遍历操作
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}想要遍历一个集合中所有的元素,那么就可以直接使用迭代器来完成:
public static void main(String[] args) {
List<String> list = Arrays.asList("A", "B", "C");
Iterator<String> iterator = list.iterator();
//每次循环一定要判断是否还有元素剩余
while (iterator.hasNext()) {
//如果有就可以继续获取到下一个元素
System.out.println(iterator.next());
}
}迭代器的使用是一次性的,用了之后就不能用了,如果需要再次进行遍历操作,那么需要重新生成一个迭代器对象。
在Java8提供了一个支持Lambda表达式的forEach方法,这个方法接受一个Consumer,也就是对遍历的每一个元素进行的操作:
public static void main(String[] args) {
List<String> list = Arrays.asList("A", "B", "C");
list.forEach(System.out::println);
}6.1.4.Queue和Deque

队列接口,它扩展了大量队列相关操作:
public interface Queue<E> extends Collection<E> {
//队列的添加操作,是在队尾进行插入(只不过List也是一样的,默认都是尾插)
//如果插入失败,会直接抛出异常
boolean add(E e);
//同样是添加操作,但是插入失败不会抛出异常
boolean offer(E e);
//移除队首元素,但是如果队列已经为空,那么会抛出异常
E remove();
//同样是移除队首元素,但是如果队列为空,会返回null
E poll();
//仅获取队首元素,不进行出队操作,但是如果队列已经为空,那么会抛出异常
E element();
//同样是仅获取队首元素,但是如果队列为空,会返回null
E peek();
}Deque双端队列:
//在双端队列中,所有的操作都有分别对应队首和队尾的
public interface Deque<E> extends Queue<E> {
//在队首进行插入操作
void addFirst(E e);
//在队尾进行插入操作
void addLast(E e);
//不用多说了吧?
boolean offerFirst(E e);
boolean offerLast(E e);
//在队首进行移除操作
E removeFirst();
//在队尾进行移除操作
E removeLast();
//不用多说了吧?
E pollFirst();
E pollLast();
//获取队首元素
E getFirst();
//获取队尾元素
E getLast();
//不用多说了吧?
E peekFirst();
E peekLast();
//从队列中删除第一个出现的指定元素
boolean removeFirstOccurrence(Object o);
//从队列中删除最后一个出现的指定元素
boolean removeLastOccurrence(Object o);
// *** 队列中继承下来的方法操作是一样的,这里就不列出了 ***
...
// *** 栈相关操作已经帮助我们定义好了 ***
//将元素推向栈顶
void push(E e);
//将元素从栈顶出栈
E pop();
// *** 集合类中继承的方法这里也不多种介绍了 ***
...
//生成反向迭代器,这个迭代器也是单向的,但是是next方法是从后往前进行遍历的
Iterator<E> descendingIterator();
}6.1.5.Set
Set支持的功能其实也就和Collection中定义的差不多,只不过:
- 不允许出现重复元素
- 不支持随机访问(不允许通过下标访问)
public interface Set<E> extends Collection<E> {
// Set集合中基本都是从Collection直接继承过来的方法,只不过对这些方法有更加特殊的定义
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
//添加元素只有在当前Set集合中不存在此元素时才会成功,如果插入重复元素,那么会失败
boolean add(E e);
//这个同样是删除指定元素
boolean remove(Object o);
boolean containsAll(Collection<?> c);
//同样是只能插入那些不重复的元素
boolean addAll(Collection<? extends E> c);
boolean retainAll(Collection<?> c);
boolean removeAll(Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
//这个方法我们同样会放到多线程中进行介绍
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT);
}
}6.1.6.Map
Map 保存键值对的形式来存储映射关系,就可以轻松地通过键找到对应的映射值:
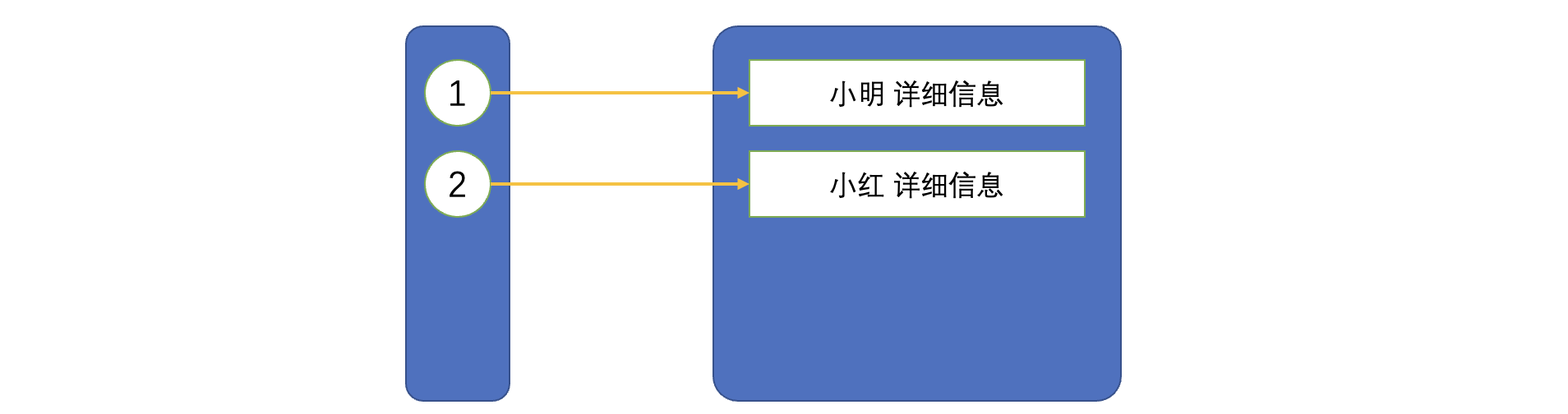
//Map并不是Collection体系下的接口,而是单独的一个体系,因为操作特殊
//这里需要填写两个泛型参数,其中K就是键的类型,V就是值的类型,比如上面的学生信息,ID一般是int,那么键就是Integer类型的,而值就是学生信息,所以说值是学生对象类型的
public interface Map<K,V> {
//-------- 查询相关操作 --------
//获取当前存储的键值对数量
int size();
//是否为空
boolean isEmpty();
//查看Map中是否包含指定的键
boolean containsKey(Object key);
//查看Map中是否包含指定的值
boolean containsValue(Object value);
//通过给定的键,返回其映射的值
V get(Object key);
//-------- 修改相关操作 --------
//向Map中添加新的映射关系,也就是新的键值对
V put(K key, V value);
//根据给定的键,移除其映射关系,也就是移除对应的键值对
V remove(Object key);
//-------- 批量操作 --------
//将另一个Map中的所有键值对添加到当前Map中
void putAll(Map<? extends K, ? extends V> m);
//清空整个Map
void clear();
//-------- 其他视图操作 --------
//返回Map中存放的所有键,以Set形式返回
Set<K> keySet();
//返回Map中存放的所有值
Collection<V> values();
//返回所有的键值对,这里用的是内部类Entry在表示
Set<Map.Entry<K, V>> entrySet();
//这个是内部接口Entry,表示一个键值对
interface Entry<K,V> {
//获取键值对的键
K getKey();
//获取键值对的值
V getValue();
//修改键值对的值
V setValue(V value);
//判断两个键值对是否相等
boolean equals(Object o);
//返回当前键值对的哈希值
int hashCode();
...
}
...
}Map中无法添加相同的键,同样的键只能存在一个,即使值不同。如果出现键相同的情况,那么会覆盖掉之前的。
6.2.Java I/O
I/O简而言之,就是输入输出,JDK提供了一套用于IO操作的框架,根据流的传输方向和读取单位,分为:
- 字节流
InputStream和OutputStream - 字符流
Reader和Writer
6.2.1.文件字节流
FileInputStream 可以通过它来获取文件的输入流:
public static void main(String[] args) {
try { //注意,IO相关操作会有很多影响因素,有可能出现异常,所以需要明确进行处理
FileInputStream inputStream = new FileInputStream("路径");
//路径支持相对路径和绝对路径
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}路径分为绝对路径和相对路径:
C://User/lbw/nb 这个就是一个绝对路径,因为是从盘符开始的
test/test 这个就是一个相对路径,因为并不是从盘符开始的,而是一个直接的路径在使用完成一个流之后,必须关闭这个流来完成对资源的释放,否则资源会被一直占用:
public static void main(String[] args) {
FileInputStream inputStream = null; //定义可以先放在try外部
try {
inputStream = new FileInputStream("路径");
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
try { //建议在finally中进行,因为关闭流是任何情况都必须要执行的!
if(inputStream != null) inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}在JDK1.7新增了try-with-resource语法,用于简化这样的写法(本质上还是和这样的操作一致,只是换了个写法):
public static void main(String[] args) {
//注意,这种语法只支持实现了AutoCloseable接口的类!
//直接在try()中定义要在完成之后释放的资源
try(FileInputStream inputStream = new FileInputStream("路径")) {
...
} catch (IOException e) {
//这里变成IOException是因为调用close()可能会出现,而FileNotFoundException是继承自IOException的
e.printStackTrace();
}
//无需再编写finally语句块,因为在最后自动帮我们调用了close()
}使用read方法读取文件里面的内容:
public static void main(String[] args) {
try(FileInputStream inputStream = new FileInputStream("test.txt")) {
//使用read()方法进行字符读取
System.out.println((char) inputStream.read()); //读取一个字节的数据(英文字母只占1字节,中文占2字节)
System.out.println(inputStream.read()); //唯一一个字节的内容已经读完了,再次读取返回-1表示没有内容了
}catch (IOException e){
e.printStackTrace();
}
}使用read可以直接读取一个字节的数据,注意,流的内容是有限的,读取一个少一个。如果想一次性全部读取的话,可以直接使用一个while循环来完成:
public static void main(String[] args) {
//test.txt:abcd
try(FileInputStream inputStream = new FileInputStream("test.txt")) {
int tmp;
//通过while循环来一次性读完内容
while ((tmp = inputStream.read()) != -1){
System.out.println((char)tmp);
}
}catch (IOException e){
e.printStackTrace();
}
}一个一个读取效率太低了,那能否一次性全部读取呢?可以预置一个合适容量的byte[]数组来存放:
public static void main(String[] args) {
//test.txt:abcd
try(FileInputStream inputStream = new FileInputStream("test.txt")) {
//可以提前准备好合适容量的byte数组来存放
byte[] bytes = new byte[inputStream.available()];
//一次性读取全部内容(返回值是读取的字节数)
System.out.println(inputStream.read(bytes));
//通过String(byte[])构造方法得到字符串
System.out.println(new String(bytes));
}catch (IOException e){
e.printStackTrace();
}
}输出流没有read()操作而是write()操作,向文件里写入内容:
public static void main(String[] args) {
try(FileOutputStream outputStream = new FileOutputStream("output.txt")) {
outputStream.write('c'); //同read一样,可以直接写入内容
outputStream.write("lbwnb".getBytes()); //也可以直接写入byte[]
outputStream.write("lbwnb".getBytes(), 0, 1); //同上输入流
outputStream.flush(); //建议在最后执行一次刷新操作(强制写入)来保证数据正确写入到硬盘文件中
}catch (IOException e){
e.printStackTrace();
}
}利用输入流和输出流,就可以轻松实现文件的拷贝了:
public static void main(String[] args) {
try(FileOutputStream outputStream = new FileOutputStream("output.txt");
FileInputStream inputStream = new FileInputStream("test.txt")) { //可以写入多个
byte[] bytes = new byte[10]; //使用长度为10的byte[]做传输媒介
int tmp; //存储本地读取字节数
while ((tmp = inputStream.read(bytes)) != -1){ //直到读取完成为止
outputStream.write(bytes, 0, tmp); //写入对应长度的数据到输出流
}
}catch (IOException e){
e.printStackTrace();
}
}6.2.2.文件字符流
字符流不同于字节,字符流是以一个具体的字符进行读取,因此它只适合读纯文本的文件,如果是其他类型的文件不适用:
public static void main(String[] args) {
try(FileReader reader = new FileReader("test.txt")){
reader.skip(1); //现在跳过的是一个字符
System.out.println((char) reader.read()); //现在是按字符进行读取,而不是字节,因此可以直接读取到中文字符
}catch (IOException e){
e.printStackTrace();
}
}字符流只支持char[]类型作为存储:
public static void main(String[] args) {
try(FileReader reader = new FileReader("test.txt")){
char[] str = new char[10];
reader.read(str);
System.out.println(str); //直接读取到char[]中
}catch (IOException e){
e.printStackTrace();
}
}练习:尝试一下用Reader和Writer来拷贝纯文本文件。